Highlights
- Overview, challenges, and solutions for bioprocess data management
- Solutions for bioprocess data visualization & statistical analysis
- Use of soft sensors in bioprocess analysis workflows
- Werum PAS-X Savvy combines data management and analytics in one platform
As a process engineer working in process development or manufacturing science, you are responsible for efficiently developing high-performing bioprocesses, ensure a robust scale-up and make sure that a commercial process remains in state of control. Consistent data management and data analysis play a critical role in the success of your pharmaceutical development and manufacturing goals. The main challenges are:
- Where is the data and how to get it?
- How to aggregate the data and make it available to analysis?
- How to analyse the data?
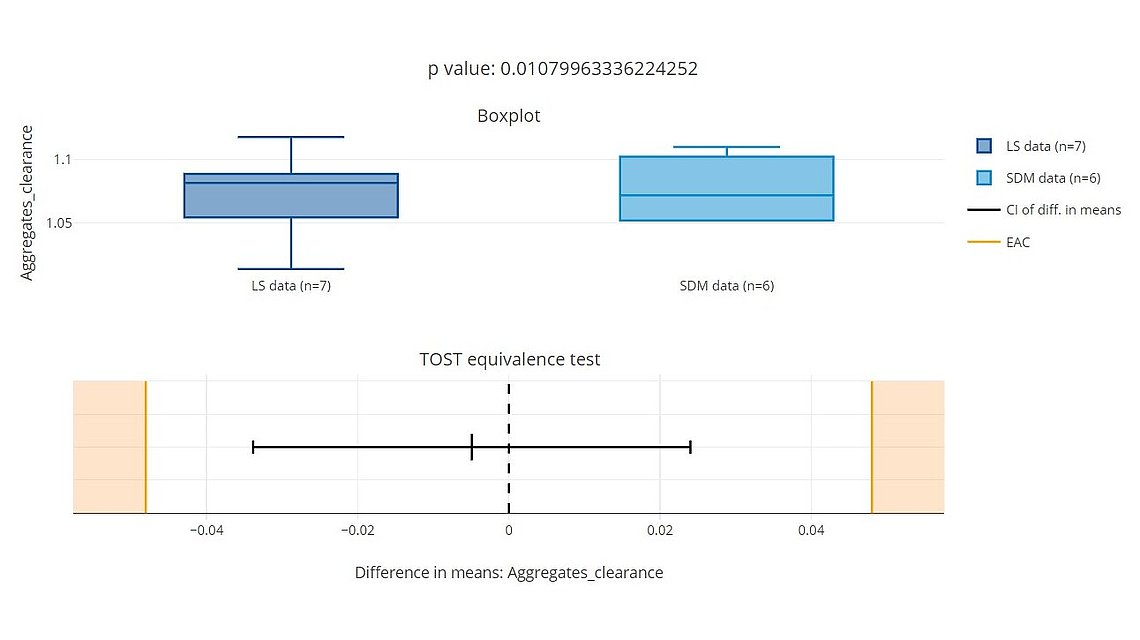
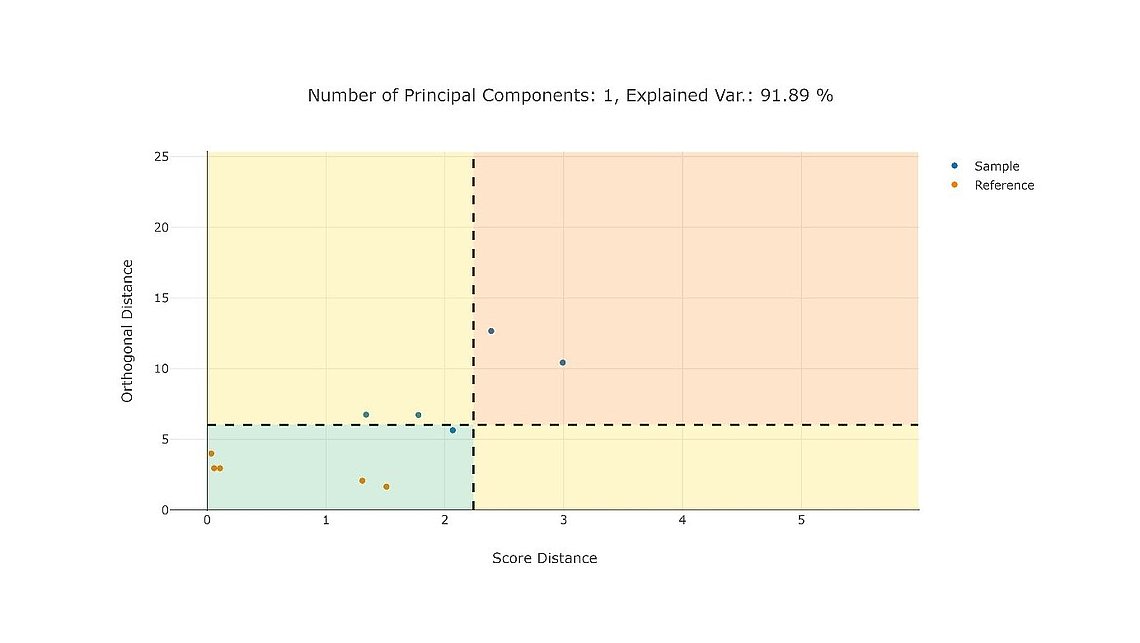
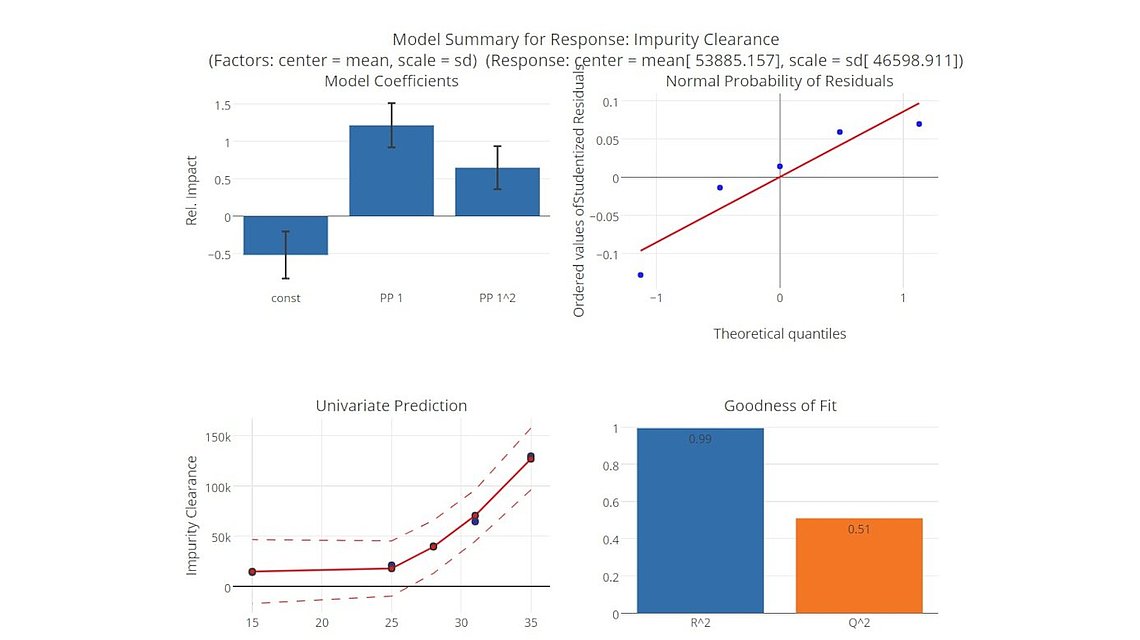
If you are working in the field of bioprocess development, scale-up process validation, or manufacturing excellence, you might frequently ask yourself: How do I get a complete and reliable overview of the process data with less effort? How to structure the ample amounts of data from different sensors in a single database? How to aggregate data from small and large scale to perform scale-down model qualifications? Which methods shall I use for pharma data analytics and the statistical evaluation of bioprocesses?
PAS-X Savvy provides a solution to all of these challenges. This article gives a brief overview of bioprocess data management, bioprocess data visualization, and statistics to evaluate bioprocesses.